文章:Dynamic Task Allocation for Robotic Edge System Resilience Using Deep Reinforcement Learning
系统恢复建模 文中所述的系统主要由多个传感器,多个机器人,一个边缘服务器,一个云数据中心组成。传感器的数据传输范围有限,只能经机器人将数据发送给数据中心。当某个机器人出现故障时,其他机器人通过改变自身位置,故障机器人,从而保证数据传输。
文章的目标是最大化系统的恢复时延率(time ratio of system recovery)和恢复完整度(success ratio)
机器人的故障产生了任务集合 $T$。任务 $t\in T$ 的恢复时延率 $\chi_t$ 是时限 $\delta_t$ 和总完成时间 $\tau_t$ 的比值,总完成时间包括机器人移动位置花费的时间及传输、运算时间。系统的恢复时延率 $\chi$ 是所有任务恢复时延率的均值。
如果一个任务的总完成时间小于任务的时限,那么视为一个成功恢复的任务。系统的恢复完整度 $\sigma$ 是成功恢复的任务在待处理任务中的占比。 $$ \begin{align} &\chi t=\frac{\delta_t}{\tau_t} \ &\tau_t=\tau{tr}^m+\tau_{tr}^u+\tau_{tr}^p+\tau_{tr}^f \ &\chi=\frac{1}{|T|}\sum_{\forall t \in T}\chi_t \ &\sigma=\frac{|T^*|}{|T|} \end{align} $$ 机器人只有在自身剩余能量大于执行任务的总能量时才能执行任务。其中执行任务的总给能量包括机器人移动的能量及传输,计算消耗的能量。
任务分配决策
边缘服务器观察 $\tau$ 时刻的状态 $$ s_\tau={L(\tau),\zeta(\tau),\delta(\tau),L’(\tau),\psi(\tau),C(\tau),\phi(\tau),v(\tau)} $$ 其中的各子项
- $L(\tau)$ 故障产生的各任务的位置
- $\zeta(\tau)$ 各任务的输入数据量
- $\delta(\tau)$ 各任务的时限
- $L’(\tau)$ 各可以执行任务的机器人的位置
- $\psi(\tau)$ 各机器人的最大可覆盖半径
- $C(\tau)$ 各机器人的运算能力
- $\phi(\tau)$ 各机器人的可用能量
- $v(\tau)$ 各机器人的速度
边缘服务器将为所有机器人决策动作 $$ a(\tau)={\mu(\tau),\nu(\tau)} $$ 其中
- $\mu(\tau)$ 各机器人需要移动至的位置
- $\nu(\tau)$ 各任务分配给哪个机器人
每一步决策后边缘服务器(智能体)将获得奖励 $$ \rho_\tau(s_\tau,a_\tau)=w_1\times\chi=w_2\times\sigma $$ 其中 $w_1$、$w_2$ 是恢复时延率和恢复完整度在奖励中的权值,和为 1
DQN训练 多个 DQN 组成评估网络 $N^E=N_1^E,N_2^E,…,N_n^E$,具有训练权值 $w^E=w_1^E,w_2^E,…w_n^E$,所有训练权值被初始化为相同值。每个 DQN 的训练目标都是能够取得最大的回报,但基于遇到过的状态训练出的 DQN 不能保证在未知状态下作出最优行动。因此文章考虑对每个模型的 Q 值进行模型不确定性统计。一开始 DQN 的每个 Q 值输出都是相同的,随着 DQN 在训练过程中预测逐渐准确,Q 值也变得更加多样化。即一个 DQN 的 Q 值标准差越大,则该 DQN 在多个 DQN 中的预测或探索准确度就越高。
在训练的每一步 $\tau$ 中,状态 $s_\tau$ 被输入进所有 DQN,每个 DQN 返回一个动作 $a_\tau^{N_i^E}$。我们将选择具有最大 Q 值标准差的 DQN 生成的动作。并从选定的 DQN 中生成的多个结果中选择能获得最大值奖励的动作。 $$ \begin{align} &a_\tau^{N_i^E}=\arg\max_{j\in|m|}Q(s_\tau,a_\tau^{N_i^E})\ &\sigma(Q(s_\tau,a_\tau^{N_i^E})j)=\sqrt{\frac{1}{m}\sum{j=1}^m(Q^{N_i^E}-\bar Q)^2}\ &\bar Q=\frac{1}{m}\sum_{j=1}^mQ(s_\tau,a_\tau^{N_i^E})_j \end{align} $$ 目标网络最初使用随机权重 $w^T$ 训练 $Y$ 步,之后每 $Y$ 步后更新权重为评估网络的权重 $w_i{^*}^E$ 取决于提供最大回报的 DQN。
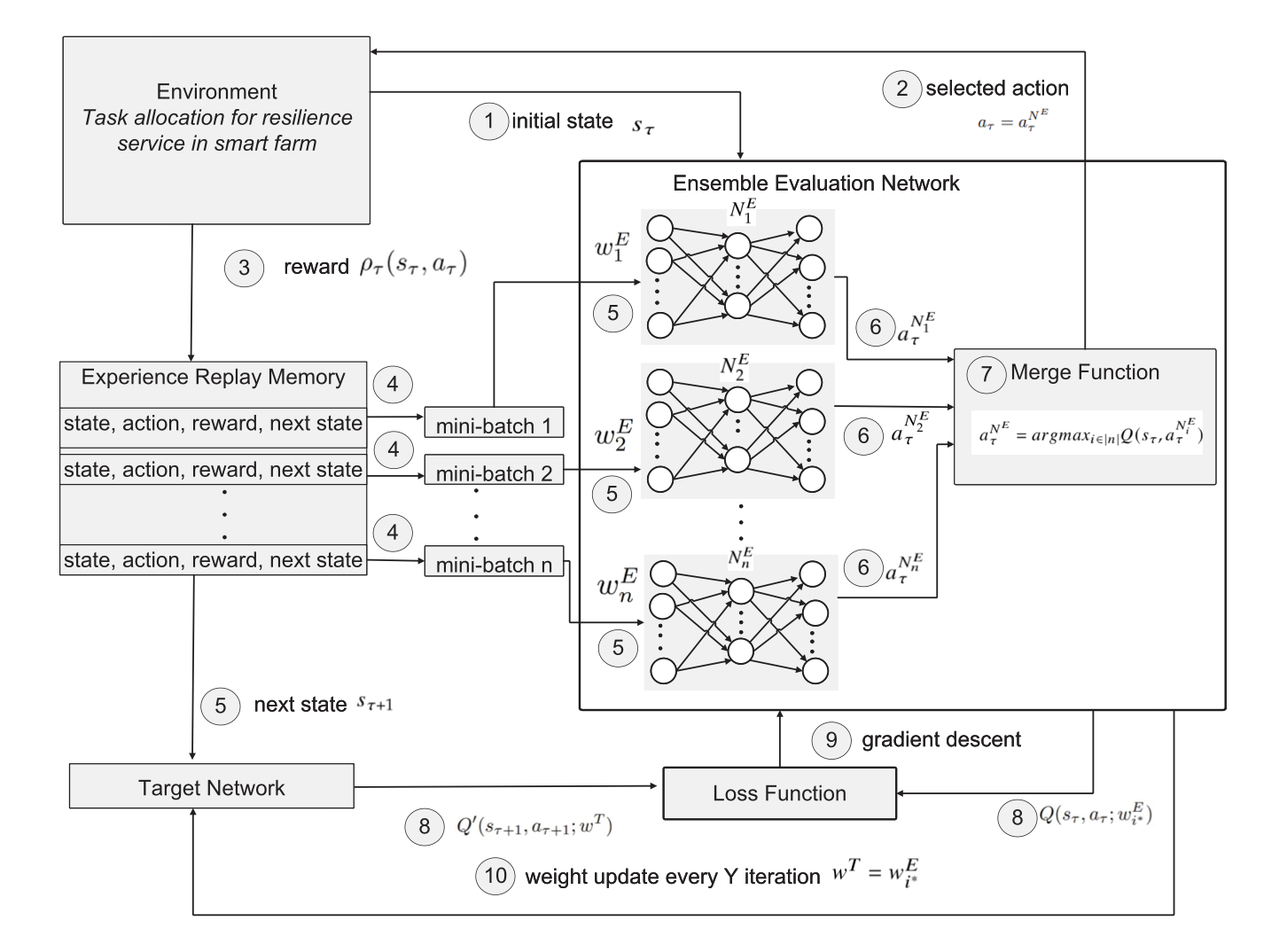
选择动作的算法图片演示与文章描述和伪代码不一致?
文章描述与伪代码是先从所有评估网络中选择 Q 值标准差最大的 DQN,然后从选定的 DQN 中选择使 Q 最大的动作;图片的描述似乎是所有 DQN 先选出一个动作,再对比所有 DQN 选出的动作,选出使 Q 值最大的动作
但是文章中列出的式$(8)$似乎又与图片中没有直接展示的所有 DQN 先选出动作的过程一致,不同的是,伪代码中左侧为 $a^{N^E}$